Resiliency of applications surpasses everything else in building customer trust. Because of this, it cannot be an afterthought. Instead of simply reacting to a failure, why not be proactive?. By Piyali Kamra, Aish Gopalan, Isael Pimentel, and Aditi Sharma.

As your system expands, you’ll likely encounter issues that can hinder your ability to scale, like security and cost. So, it’s necessary to think about the correct architectural patterns beforehand to minimize your chances of enduring a failure without a recovery plan.
The inetresting parts in the article:
- Example use case
- Pattern 1: Microservices
- Pattern 2: Saga pattern
- Pattern 3: Event-driven architecture
- Pattern 4: Cache pattern
- Improving application resiliency with bounded contexts
Distributed systems can use all of these patterns, which helps improve resiliency at the application layer. Applying these patterns, along with the Infrastructure and Operations improvements will provide frameworks for resilient applications. Nice one!
[Read More]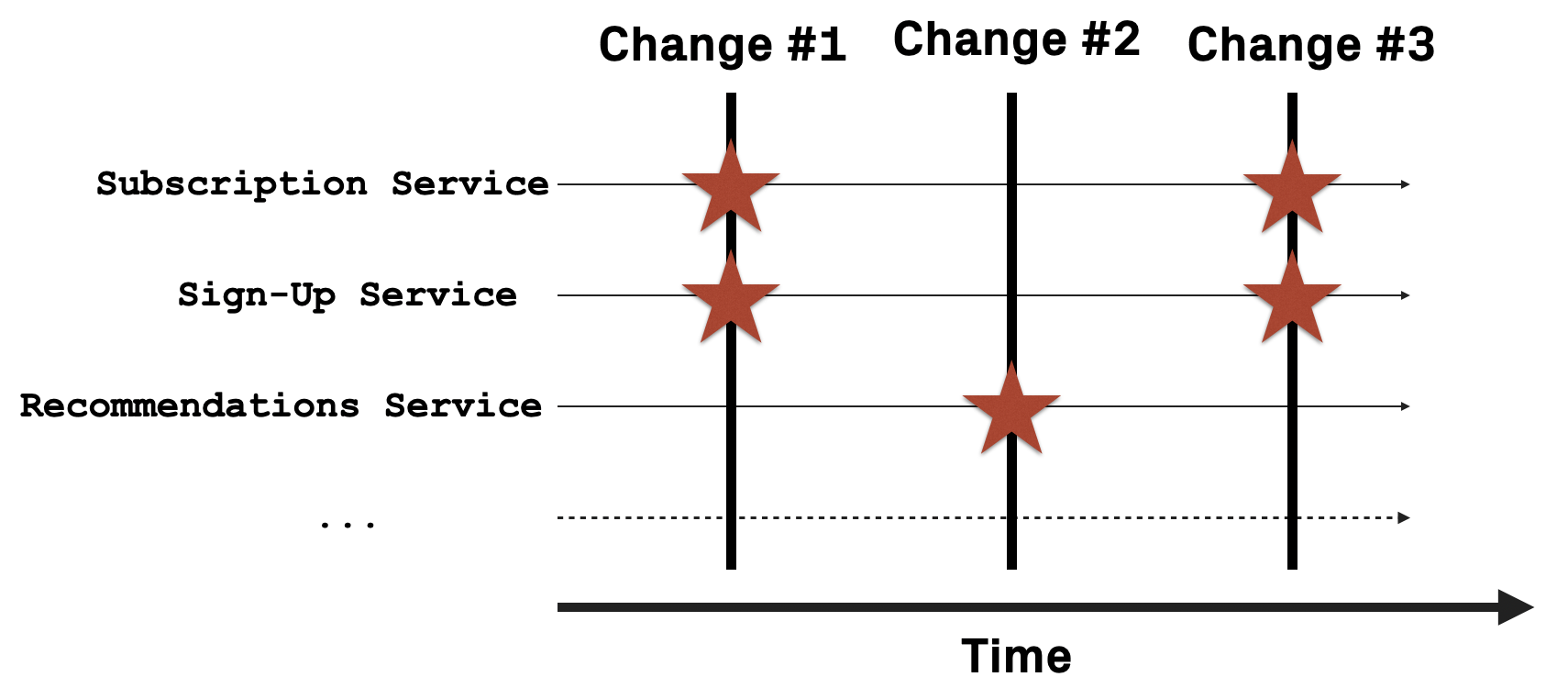 modules repeatedly change together over time., Source: https://codescene.com/blog/visualize-microservice-dependencies-in-team-context/")